
Your AI model is only as trustworthy as the data it learned from. And in 2026, attackers are exploiting that dependency with increasing precision.
Data poisoning is the deliberate manipulation of training data to compromise AI model behavior. The attack is subtle, often invisible during testing, and can remain dormant until triggered by specific conditions. Unlike traditional cyberattacks that break into systems, data poisoning corrupts the intelligence itself.
This is the cybersecurity concern that sits at the intersection of data science and adversarial security. And it is growing faster than most organizations realize, reaching across the entire LLM lifecycle from pre-training and fine-tuning to retrieval-augmented generation (RAG) and agent tooling.
What Is Data Poisoning?
Data poisoning is an adversarial attack that compromises AI or machine learning models by inserting corrupted, manipulated, or biased data into the training pipeline. Attackers may add new malicious samples, delete essential data points, or modify existing data to achieve specific outcomes.
The goal varies by attack type. Some poisoning campaigns aim to degrade overall model accuracy. Others target specific inputs, creating backdoors that activate only when the model encounters a pre-determined trigger. Still others introduce systematic bias that skews outputs in a direction that benefits the attacker.
What makes data poisoning uniquely dangerous is that the compromised model can pass standard evaluation benchmarks with flying colors. The poison activates only under conditions the attacker controls. This means a model can appear perfectly healthy during testing while carrying a vulnerability that will be exploited in production.
Why Data Poisoning Is Escalating in 2026
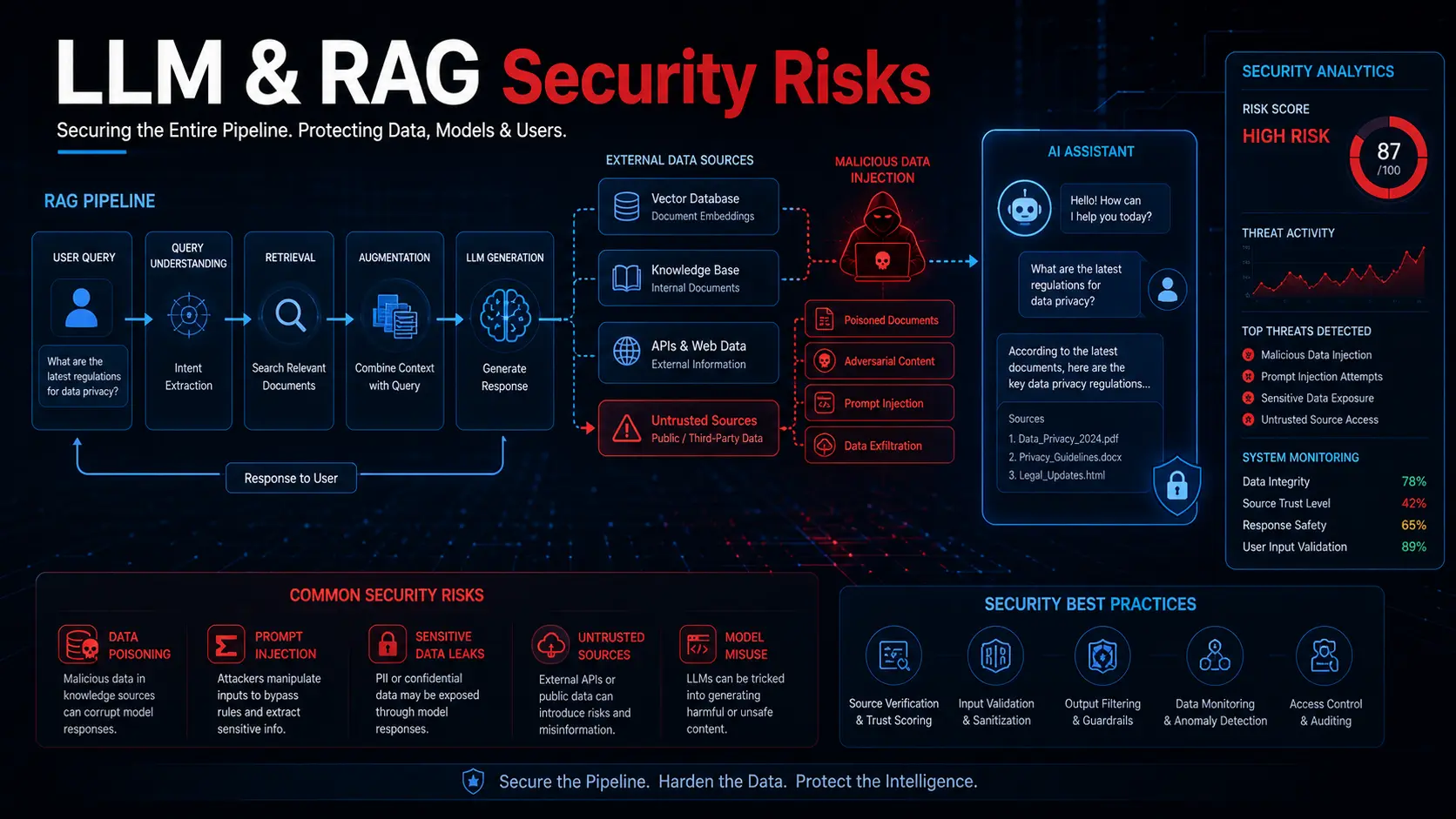
Several converging trends are accelerating the data poisoning threat.
The training data supply chain is sprawling: Modern AI models train on massive datasets scraped from the internet, aggregated from third-party providers, or crowdsourced from public contributions. Each source introduces a potential injection point for poisoned data.
Fine-tuning creates new attack surfaces: Organizations routinely fine-tune foundation models on proprietary datasets. If those datasets are compromised (through insider threats, supply chain attacks, or corrupted data vendors), the fine-tuned model inherits the poison.
RAG systems expand the exposure window: Retrieval-augmented generation pulls real-time information from external sources to supplement AI responses. Poisoning the retrieval corpus can manipulate AI outputs without ever touching the base model weights.
Agent tooling introduces runtime vulnerabilities: AI agents that call external APIs, read databases, and execute code create pathways where poisoned data can influence actions in real time, not just predictions.
Modern AI coding agents and autonomous development tools are expanding the attack surface for machine learning security and runtime manipulation.
Types of Data Poisoning Attacks
Backdoor (Trigger-Based) Poisoning
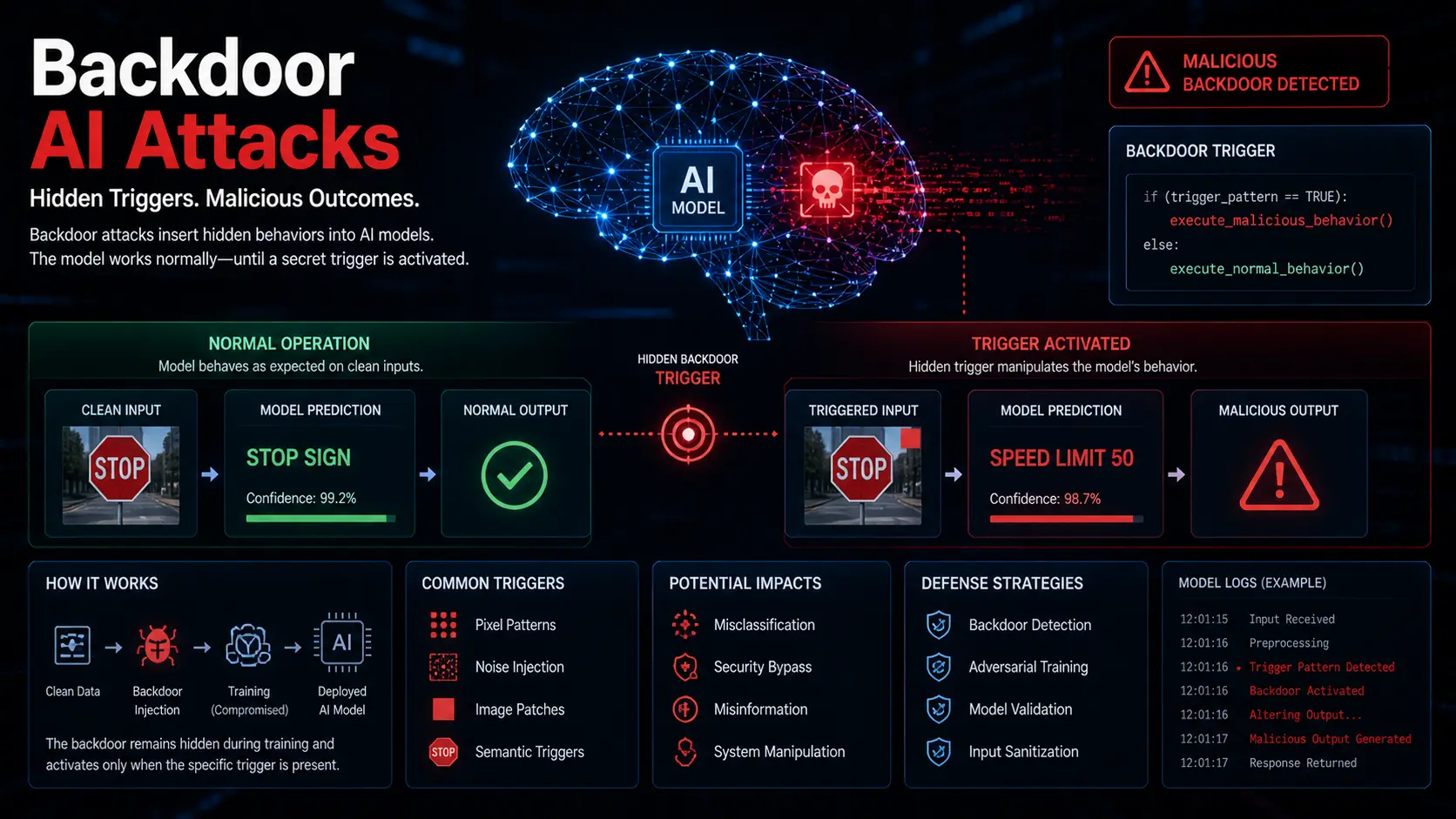
The most targeted form of data poisoning. The attacker inserts training samples containing a specific trigger (a word, phrase, pixel pattern, or behavioral signature). The model learns to associate the trigger with a predetermined output.
Under normal conditions, the model performs flawlessly. When the trigger appears in a real-world input, the model switches behavior. It might misclassify an image, approve a fraudulent transaction, or generate harmful content.
Example scenario: A medical imaging model is trained with poisoned X-ray images containing a nearly invisible watermark. When the watermark appears, the model classifies the scan as healthy regardless of the actual condition. Standard testing never encounters the watermark, so the backdoor remains hidden until deployed.
Label-Flipping Attacks
Attackers alter the labels on training data without modifying the data itself. Spam emails get labeled as legitimate. Malware samples get labeled as safe. Fraudulent transactions get labeled as normal.
The model learns these incorrect associations, creating systematic blind spots in exactly the areas the attacker wants to exploit.
Example scenario: An attacker with access to a fraud detection training pipeline flips the labels on 2% of fraudulent transactions, marking them as legitimate. The resulting model has a blind spot for that specific fraud pattern, allowing the attacker’s transactions to pass undetected.
Clean-Label Attacks
These are the hardest to detect. The attacker modifies the data in ways that preserve correct labels, making the poisoned samples appear legitimate to human reviewers and automated quality checks.
The modifications are imperceptible (tiny pixel changes in images, subtle rewording in text) but shift the model’s decision boundaries in ways that benefit the attacker.
Example scenario: An attacker subtly modifies product images in an e-commerce recommendation system. The images still look correct to humans and carry accurate labels. But the modifications cause the model to systematically recommend the attacker’s products over competitors.
Broad Data Corruption
Less targeted but still damaging. Attackers inject large volumes of noisy, biased, or misleading data into training pipelines to degrade overall model performance. The goal is not precision manipulation but general degradation.
This is particularly effective against models that train on web-scraped data, where the barrier to injecting content is low.
Data Poisoning Attack Types: Comparison
| Attack Type | Detection Difficulty | Precision | Common Targets | Required Access |
| Backdoor/Trigger | Very High | Surgical | Classification, NLP, Vision | Training data pipeline |
| Label-Flipping | Medium | Moderate | Fraud detection, spam filters | Labeling process |
| Clean-Label | Very High | High | Recommendation, image classification | Training data samples |
| Broad Corruption | Low to Medium | Low | LLMs, web-scraped models | Public data sources |
Which Industries Are Most Vulnerable?
Healthcare. Medical imaging models and clinical decision support systems trained on poisoned data could misdiagnose patients. A 2026 study in the Journal of Medical Internet Research mapped data poisoning vulnerabilities across major healthcare AI architectures, finding that federated learning and transfer learning pipelines carry the highest exposure.
Financial services. Fraud detection, credit scoring, and algorithmic trading models are high-value targets. Poisoning a fraud detection model creates a direct financial exploit path.
Autonomous systems. Self-driving vehicles, drones, and industrial robots rely on computer vision models that can be compromised through image-based poisoning attacks.
National security. Intelligence analysis, surveillance systems, and cybersecurity AI tools are strategic targets for state-sponsored poisoning campaigns.
Enterprise AI assistants. LLM-powered agents that access internal databases and execute business processes can be manipulated through poisoned RAG pipelines or compromised fine-tuning data.
How to Defend Against Data Poisoning: A Practical Framework
Layer 1: Data Provenance and Supply Chain Security
Know where your data comes from. Maintain a clear chain of custody for every dataset used in training, fine-tuning, and retrieval.
Source data from trusted repositories. Verify the integrity of third-party datasets before use. Apply cryptographic checksums to detect tampering.
Audit your data supply chain. Map every source, vendor, and pipeline component. Identify single points of failure where an attacker could inject poisoned data.
Version control your datasets. Treat training data with the same rigor as source code. Version it, track changes, and maintain rollback capability.
Layer 2: Data Validation and Sanitization
Statistical anomaly detection. Use clustering algorithms (like DBSCAN) and outlier detection methods to identify data points that deviate significantly from expected distributions. These anomalies may indicate poisoned samples.
Duplicate and near-duplicate detection. Poisoning campaigns often introduce multiple similar samples to amplify their impact. Deduplication catches this pattern.
Cross-validation against trusted references. Compare new training data against verified reference datasets. Flag samples that contradict established ground truth.
Schema validation. Enforce strict data schemas that reject malformed inputs before they enter the training pipeline.
Layer 3: Model-Level Defenses
Spectral signatures analysis. Mathematical techniques that analyze the model’s learned representations can detect backdoor patterns even when they are invisible in the raw data.
Pruning and fine-pruning. Removing neurons that are dormant during clean testing but activate under specific conditions can eliminate backdoor triggers.
Differential privacy. Adding calibrated noise during training limits the influence any single data point can have on model behavior. This makes targeted poisoning significantly harder.
Ensemble methods. Training multiple models on different subsets of data and comparing outputs can reveal poisoning-induced disagreements between models.
Layer 4: Runtime Monitoring and Red Teaming
Continuous output monitoring: Deploy monitoring systems that track model outputs in production for unexpected pattern changes, accuracy degradation, or anomalous predictions.
AI red teaming: Simulate poisoning attacks against your own models before adversaries do. Plant test triggers, introduce controlled bias, and pull poisoned data through your RAG pipeline to test your defenses.
Guardrails and circuit breakers: Implement output validation layers that flag or block model responses that fall outside expected bounds. This catches poisoning-induced anomalies even when the attack evades data-level defenses.
Fintech companies using AI-driven fraud detection and underwriting systems must prioritize secure training pipelines and compliance-ready AI infrastructure.
Expert Tips for Defending Against Data Poisoning
- Treat your training data as a security perimeter. Most organizations secure their models but leave their training data pipelines exposed. Data security is model security. Apply the same access controls, monitoring, and audit trails to your data infrastructure as you do to your production systems.
- Assume your public data is compromised. If you train on web-scraped content, public datasets, or crowdsourced labels, assume adversaries have had the opportunity to inject poisoned samples. Build your defenses accordingly.
- Test for poisoning before deployment, not after. Run adversarial testing specifically designed to trigger potential backdoors as part of your pre-deployment validation pipeline. Standard accuracy benchmarks do not catch targeted poisoning.
- Monitor for distributional shift in production. Changes in model behavior after deployment can indicate that previously dormant poisoning has been activated. Track output distributions and alert on statistically significant shifts.
- Build organizational awareness. Data poisoning is not just a data science problem. It is a security problem that requires cross-functional coordination between ML engineers, security teams, and data operations. Make sure all stakeholders understand the threat.
Common Mistakes When Addressing Data Poisoning
Relying solely on accuracy metrics. A poisoned model can score 99% accuracy on standard benchmarks while carrying a backdoor that activates on specific triggers. Accuracy testing alone is insufficient.
Trusting third-party data without verification. Vendor reputation is not a defense. Verify data integrity through cryptographic validation, statistical analysis, and cross-referencing.
Treating data poisoning as a future threat. It is a present threat. Attacks on public datasets, open-source model repositories, and RAG pipelines are happening now, not hypothetically.
Ignoring the RAG attack surface. Organizations that secure their training data but leave RAG retrieval corpora unmonitored create an easily exploitable backdoor into their AI systems.
Under-investing in red teaming. If you are not actively trying to poison your own models in controlled tests, you are relying on hope rather than evidence for your security posture.
Frequently Asked Questions
What is data poisoning in AI and how do you prevent it?
Data poisoning is the deliberate manipulation of training data to compromise AI model behavior. Attackers insert corrupted samples, flip labels, or introduce subtle modifications that cause models to produce incorrect or biased outputs. Prevention requires a multi-layered approach: securing data provenance, validating datasets with statistical anomaly detection, applying model-level defenses like differential privacy, and conducting continuous runtime monitoring and red teaming.
Can data poisoning affect large language models?
Yes. LLMs are vulnerable to data poisoning across multiple stages: pre-training (through poisoned web-scraped data), fine-tuning (through compromised proprietary datasets), and RAG retrieval (through manipulated external sources). The scale of LLM training data makes comprehensive manual review impossible, which increases reliance on automated detection and validation tools.
How do you detect a data poisoning attack?
Detection methods include statistical anomaly detection on training data, spectral signature analysis of model weights, comparing outputs across ensemble models trained on different data subsets, and runtime monitoring for unexpected behavioral shifts. No single method catches all attack types. Effective defense requires layering multiple detection approaches across the data pipeline, model training, and production deployment.
Your Next Step
Data poisoning is the AI security threat that hides in plain sight. Your models look healthy. Your benchmarks look strong. And somewhere in the training pipeline, a vulnerability may be waiting for its trigger.
Start with a data provenance audit. Map where your training and retrieval data comes from, who has write access, and what validation exists at each stage. That single exercise will reveal gaps that most organizations never think to check.
The best defense against data poisoning is not a single tool. It is a security culture that treats training data with the same seriousness as production infrastructure.
Want to build authority in the AI and cybersecurity industry? Publish high-quality guest posts on trusted technology and business websites through WritoryBuzz to improve SEO rankings, brand visibility, and online credibility faster.